字符编码-锟斤拷�⊠是怎样炼成的
计算机显示文字原理
三个概念:字符、字符集和字符编码
申,@,2… 世界上各种语言里的字和标点符号,甚至emoji表情🥰,都属于字符(Character)。一堆字符组成的集合,叫做字符集(Character Set)通常情况下,字符集里不含重复字符为了让计算机认识这些字符,就需要把字符用0和1表示出来,这套转换的规则,叫做字符编码(Character Encoding)。
每个字符唯一的编号称为码点(Code Point)。字符范围称为码空间(Code Space),码空间越大,字符集就越大
发展史
ASCII
计算机存储数据的基本单位是字节Byte,一个字节由8个二进制位组成,也就是可以表示256个字符,这对于英文来说已经够了,故有了美国信息交换标准代码ASCII,收录了128个字符。如字母A的ASCII编号为65,转换为二进制为1000001
EASCII
西欧用剩下的128个空位表示其他字符,也就是EASCII-扩展美国信息交换标准代码。问题是:各国的EASCII字符集和编码后面128个字符都不太一样,一共有两百多种EASCII且互不兼容
同样一串二进制数在不同的EASCII中对应的字符也不同,所以同一份文本放在不同语言的计算机中打开都会出现乱码
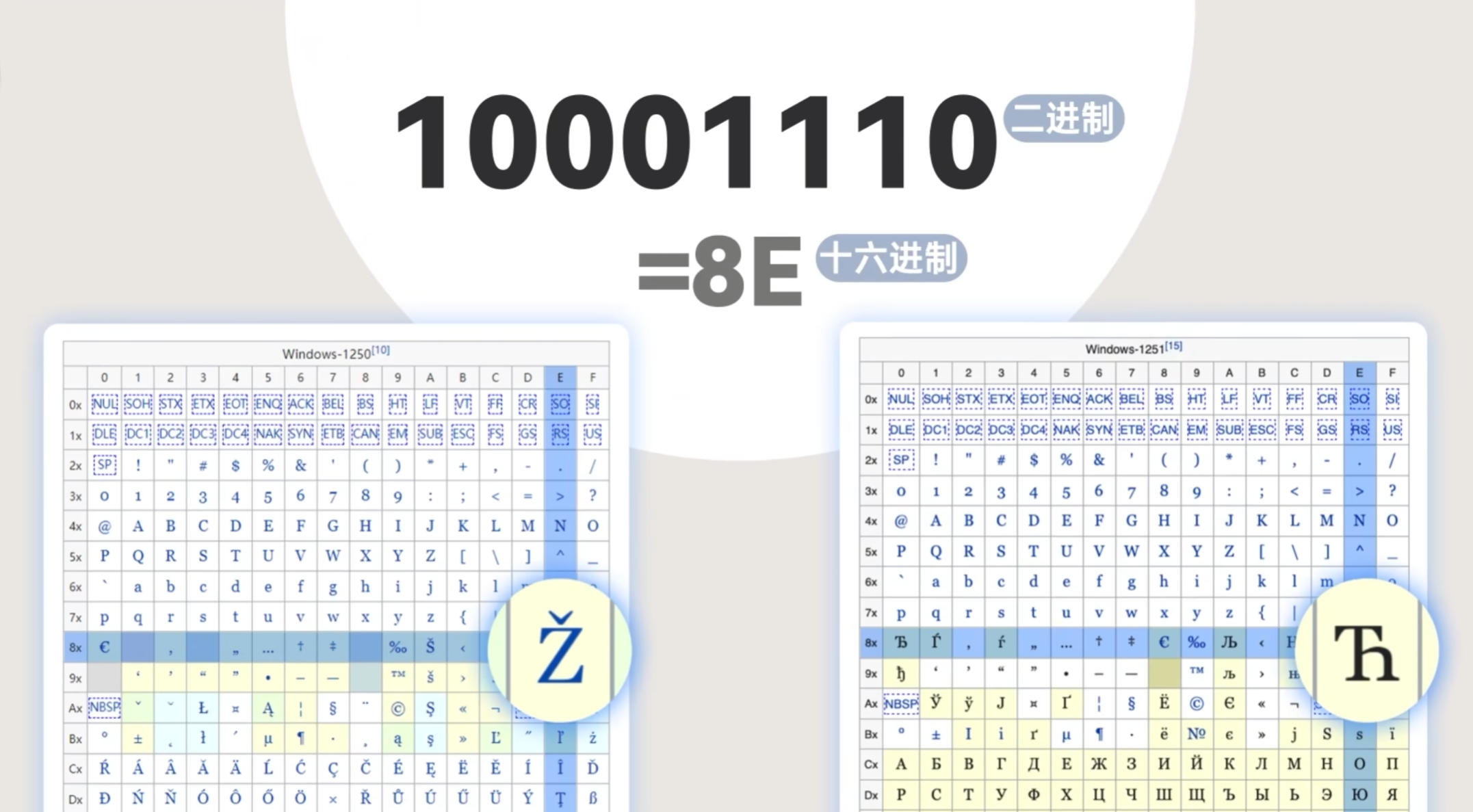
直到中日韩字库三巨头的加入,就要面临:汉字
GB 2312-80
信息交换用汉字编码字符集-基本集(仅有六千多个汉字),一个字节256个字符根本不够用,所以GB 2312就用两个字节编码一个字符,那么理论上就可以容纳65536个字符。
输入法中的全角标点符号就是用两个字节来编码,而半角标点符号用一个字节编码
而且还涉及到了字体问题,如仿宋GB2312意思是就是只设计了GB2312字符集中的字符,否则计算机就会调用其他字体来显示,或者直接显示个框框
下一个问题:汉字有简体和繁体,中日韩每个国家的汉字也不相同


GBK
于是微软在GB2312的基础上加入了繁体汉字,有了GBK-汉字内码扩展规范,GBK(GuojiaBiaozhunKuozhan),用拼音首字母缩写可还行。不过GBK并不是国家标准,只是一个普通的技术规范。收录了21886个汉字和图形符号,汉字占了21003个
Unicode-人类文明编码界的巴别塔
也称为万国码或者统一码,包含了25种文字,1114112(17*65536)个码位(还收录了214个康熙部首,被列为兼容字符,用户很难输入
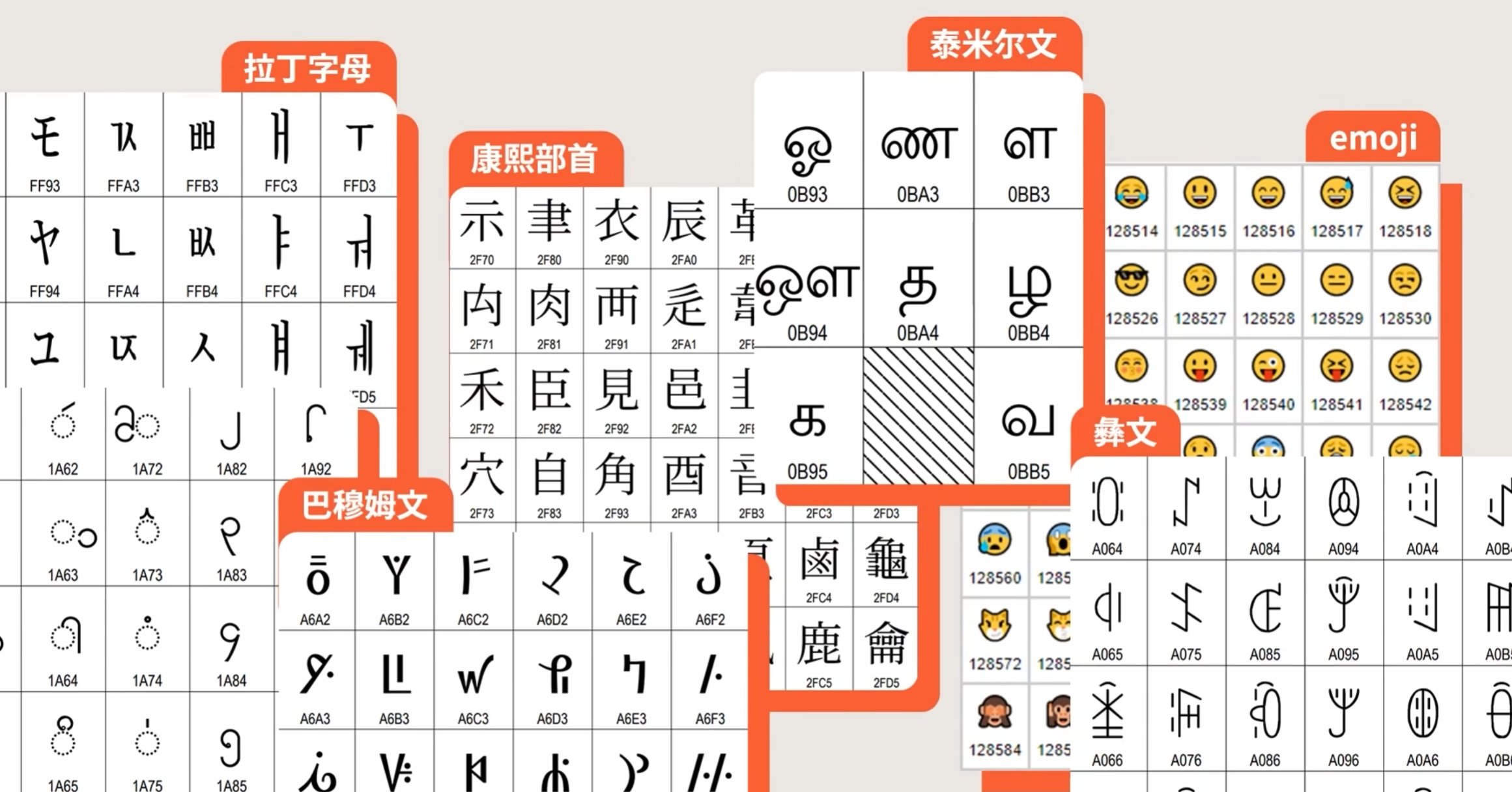
以书写系统为标准,对字符进行分类和收录:
- 拉丁字母:英语、德语、法语、西班牙语等
- 中日韩统一表意文字:简繁体字、日本汉字、朝鲜汉字等,为了节省码位,Unicode就让相似的字共用一个码位
Unicode码位甚至还有为各个国家、地区或者企业准备的私用区PUA-A/B(Private Use Area Planes),供自定义使用。比如:
- 苹果就把自己的logo放进了私用区,只有苹果系统能正常显示,安卓等其它系统就会显示乱码
- 《星际迷航》的影迷就把克林贡文字放进了私用区,只要安装相关软件和字体,就能输入和显示克林贡语
| 字符集 | 编码方式 |
|---|---|
| ASCII | ASCII编码 |
| GB2312 | EUC-CN编码 |
| GBK | GBK编码 |
| Unicode | UTF-8/16/32编码 |
可见,大多数字符集都只有一种编码方式,而Unicode有多种编码方式。目前UTF-8(Unicode Transformation Format -8- bit)的适应性最好,也更广泛,其次是GBK。所以同一串二进制数字,用错误的编码方式打开就会导致乱码
UTF-8的特点:
- 对于ASCII字符,UTF-8用一个字节表示,与传统的ASCII编码兼容
- 对于非ASCII字符,使用多个字节,字节的数量取决于字符的Unicode码点范围
Unicode官网:https://home.unicode.org/ 可以查看Unicode标准文档,进行字符搜索、测试等
应用
- 利用文字编码来降低热搜:(换个字体即可发现端倪

- 锟斤拷:以GBK编码方式保存,用UTF-8的编码方式打开,无法正常显示,Unicode就用字符�进行替代。再次点击保存,�就全被编码为了
0xEF BF BD,然后再使用GBK编码打开,根据规则,连续两个�,那么EFBF,BDEF,BFBD三个码位分别对应的就是锟!斤!拷!
在Win7,Win8以及Win10的早期版本,记事本默认用的就是ANSI(American National Standards Institute)编码,而ANSI在不同语言系统中对应的实际编码不同。在简体中文系统中,就是GBK编码;在英文系统中,就是Windows-1252编码(EASCII的一种)。如今Win11记事本已经默认使用UTF-8编码
所以必须保证文本的编码和解码都使用同一套规则,才可以正确显示
- Emoji冷知识:Emoji最早是日本移动通信产业和其他聊天软件自己开发的。后来随着使用范围越来越广,Unicode联盟开始正式纳入Emoji到Unicode标准中。但只规定了emoji的含义,并不管具体长什么样,所以决定emoji显示样式的,是emoji字体(Mac和Windows使用的emoji字体不相同)