resnet残差网络-环境配置
基本概念
混淆矩阵
confusion matrix 也叫误差矩阵,是用于评估分类模型性能的重要工具,可以展示分类准确性。用n*n的矩阵来表示,通常用于二分类,也可以扩展到多分类问题。
在二分类中,混淆矩阵包含四个条目:
- 真正例
True Positives表示模型成功检测正类别 - 真负例
True Negatives成功检测负类别 - 假正例
False Positives错误将负类别样本分类为正类别 - 假负例
False Negatives错误将正类别样本分类为负类别
| 预测为正例 | 预测为负例 | |
|---|---|---|
| 实际为正例 | TP | FN |
| 实际为负例 | FP | TN |
横纵坐标对不上可以通过转置来解决
这四个条目可以用于计算分类性能指标:
- 准确率
Accuracy模型正确分类与总样本数的比例:(TP+TN)/总样本数 - 精确率
Precision表示正类别样本中被正确分类的比例:TP/(TP+FP) - 召回率
Recall成功识别正类别样本的比例:TP/(TP+FN) - F1分数
F1 Score:精确率和召回率的调和平均值,用于考虑模型的综合性能
导入方式:from sklearn.metrics import confusion_matrix
参数:
- y_true:实际标签(一维数组或列表)
- y_pred:预测标签
- labels:默认情况下考虑所有不同类别,如果指定此参数,可以限定要考虑的类别
- normalize:默认值为False,若设置为true,则为百分比形式,而不是计数
标签中有几种类别,那么混淆矩阵就是几维的
卷积神经网络
卷积是一个数学概念,将两个函数中的一个进行翻转然后滑动叠加,叠加是指对两个函数的乘积求积分,在不同领域有不同解释:信号分析:卷积被用来计算输入信号对系统产生影响的累计效果;概率论,卷积被用来计算二维随机变量的概率密度;经济学:卷积被用来计算连续复利……然而最有趣的还是卷积在机器学习上的应用
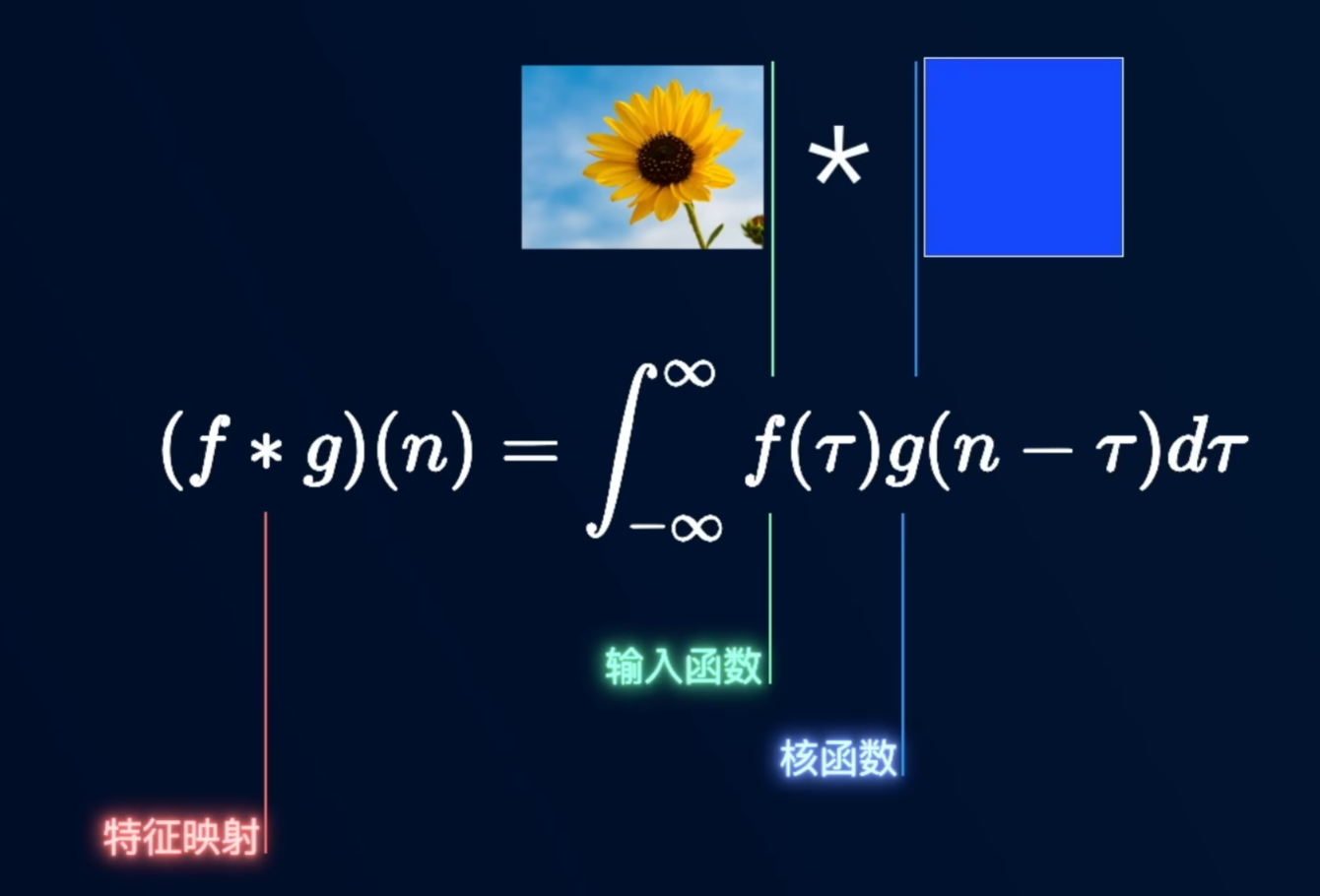
核函数(卷积核)需要人为构建,一般是个3*3的矩阵。图像卷积在不同的卷积核下具有不同意义:(设计卷积核是一门艺术
- 若卷积核数值全为1/9(即
3*3矩阵,每个位置的权重相等,卷积核内的每个像素对输出像素的贡献相同),相当于取九个数的平均值作为中间值,起到平滑和模糊的效果,降低图像细节和噪声,这叫做均值滤波,此时的卷积核是一种线性滤波器,滤波器越大(5*5矩阵),图像细节就损失越多。在python中对应的是cv2.blur函数 - 高斯卷积核:用于实现高斯模糊。权重不均匀,根据高斯分布(正态分布)来分配。高斯分布有两个参数:均值和标准差(方差),完全描述了分布的形状,即中心像素的权重最高,周围像素权重逐渐减小。相较于均值滤波,有着更好的平滑效果
- 边缘增强卷积核:中间数值是9,用于放大中心像素的强度,其他都为-1:用于减少周围像素的强度。通过增强像素周围的对比度,实现锐化或边缘增强的效果,可用于图像增强和特征增强的任务
- 第一列1,第二列0,第三列-1卷积核:相当于求了图像水平方向的一阶导数,可得图像的轮廓
在机器学习中,不管是图像、语音还是本文,都会被计算机转换为矩阵或矩阵的序列。机器学习算法会用卷积核提取图像特征,即特征矩阵,再用另外的卷积核,对特征矩阵进一步简化,最后得到含义更简单的特征

组成部分:
- 卷积层
Convolutional Layer提取特征:卷积操作是将一个小的滤波器(卷积核)在输入数据上滑动并执行元素级的乘法并累加来实现的,可以捕捉数据的局部特征 - 池化层
Pooling Layer:在保留重要特征的基础上,减小特征图的空间尺寸以降低计算复杂性。 - 激活函数
Activation Function:在卷积层和全连接层之间应用非线性激活函数,如ReLURectified Linear Unit,帮助网络捕捉更复杂的模式 - 全连接层
Fully Connected Layer:在网络的末尾通常包括一个或多个全连接层,用于将前面卷积和池化操作得到的特征映射转换为最终的输出。一般与softmax函数结合,用于多类别分类任务
特点:
- 权重共享:在卷积层中,同一卷积核会被应用到输入数据的不同位置,减少了网络参数数量,提高模型的拟合能力
- 层级结构:CNN具有多个卷积层和池化层,底层的卷积层捕捉低级特征,深层次的卷积层捕捉更抽象和高级的特征
搭建虚拟环境
使用Anaconda进行环境管理:
- 进入默认的base环境,cmd输入
activate或直接打开Anaconda Prompt都行 - 创建环境
conda create -n yyyy python=3.7,在pycharm添加解释器时,也可以创建虚拟环境
conda info --envs查看环境conda activate "name"进入环境conda deactivate退出环境conda remove -n yyyy --all删除名为yyyy的虚拟环境及其所有依赖项
可以进入Anaconda进行可视化管理,创建的环境默认有11个包
CUDA介绍
Compute Unified Device Architecture是NVIDIA开发的并行计算平台和应用程序编程接口,允许使用英伟达显卡的计算能力来加速程序运行,特别是大规模数据处理(深度学习)领域的应用。在开发深度学习模型时使用支持CUDA的框架(Pytorch或Tensorflow),那么就可以将训练从CPU转移到GPU上。理解:就是给GPU运算提供一个平台
虚拟环境和CUDA的关系
在Anaconda中,安装的CUDA是全局安装,并不是特定于某个虚拟环境。在环境中使用框架时,会自动检测系统是否安装CUDA
CUDA是系统级组件,虚拟环境是Python环境的隔离容器,主要用于管理包的依赖关系,而不涉及系统组件的安装。想要在虚拟环境中使用CUDA,只需确保在环境中安装支持CUDA的深度学习框架
安装CUDA需要考虑的兼容性
- GPU类型:不同的GPU支持不同的CUDA
cmd运行nvidia-smi
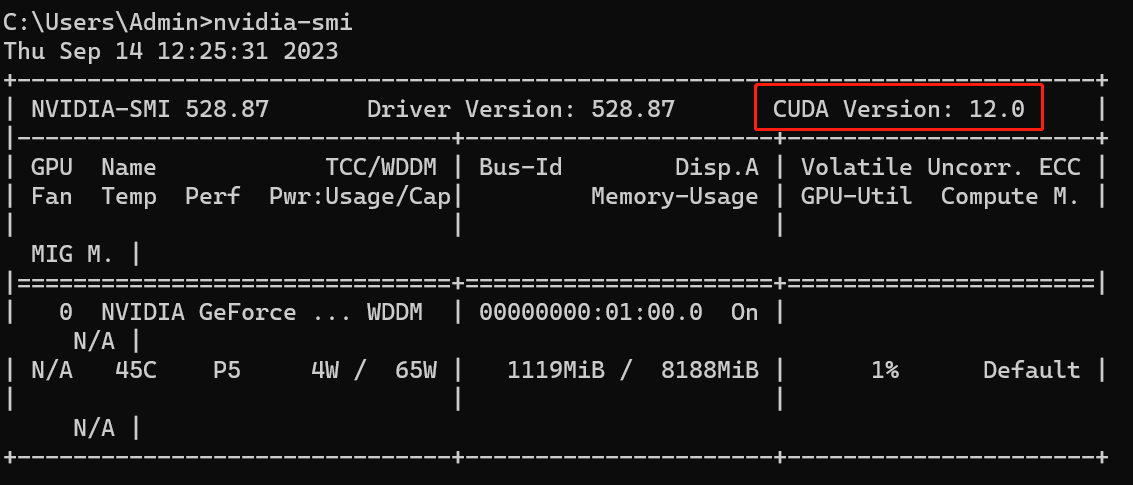
检查本机显卡支持的最高CUDA版本,即12.0,这里安装11.7.1:CUDA下载官网,选择11.7.1,安装时,第一次会让设置临时解压目录(默认即可,安装结束后自动删除),第二次设置安装目录,所以:不要把临时解压目录和安装目录设置为相同的,否则会找不到安装目录。安装选项取消VS,然后安装
验证:cmd运行nvcc -V,输出版本号即代表安装成功
- 深度学习框架版本:在pytorch的github官网发布页,每个发布都对应了其支持的CUDA版本
使用注意
简单的print语句不需要利用GPU,只有训练模型或进行复杂张量运算才能用到。最起码要编写一个涉及深度学习操作的脚本
cuDNN
CUDA Deep Neural Network library是GPU加速库,可以加速卷积操作,池化操作等
安装:
- 官网(要注册账号)
- 找到适配CUDA11.x的,下载
- 解压,复制三个文件夹,粘贴到CUDA的安装目录
Pytorch
- 官网
- 运行命令
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia,报错:ClobberError,原因:conda和pip的版本太低,解决:
conda clean --allconda update --all或者:- 重新创建环境,指定python=3.10
查看torch版本:print(torch.__version__)
最后检查GPU是否可用:(即是否正确安装了CUDA和Torch
1 | import torch |
但是在只有torch的虚拟环境中运行,其他的一些import就会找不到,需要在此环境中单独安装,已安装:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tensorboard tqdm matplotlib scikit-learn PyQt5 pyqt5-tools qt-material pandas openpyxl
安装pyqt5-tools工具包后,就可以使用qt designer
至此,虚拟环境,以及在独显上跑神经网络就已经配置好了